
Index
Básico
- Macrodatos: Big data
- Data mining / Minería de datos
- Web mining
- Text mining
- Método descriptivo
- Método predictivo
- Transformación digital
- THE DATA SCIENCE VENN DIAGRAM
- Analyzing the Analyzers
- Machine Learning - Aprendizaje automático
- Deep Learning - Aprendizaje profundo
- IoT - Internet of Things
- Anonimización de los datos
- Datos generados por humanos
- Datos generados por máquinas
- SQL
- Almacenamiento distribuido
- Almacenamiento en la nube
- Cómputo en la nube
- GIGO
- ETL
- Seguimiento y detección de anomalías
- Analisis de Texto
- Análisis predictivo
- Visualización
- Inteligencia de negocios - Business intelligence
- Gobierno de datos
- Ciclo de vida de los datos
- Modelo de datos
- Conocimiento del cliente
- Análisis exploratorio y estadístico
- Ciencia de datos
- Mostrar los valores en los datos
- ¿Qué gráfico usar?
- Composición, distribución y correlación de los datos
- Visualización Vs. Historia
- Errores
Intermedio
- Ciencia de datos
- SQL
- ETL- Extract, Transform and Load
- NoSQL
- Limpieza de datos
- Estadística descriptiva
- Analítica predictiva
- Minería de datos o exploración de datos
- CRISP-DM Cross Industry Standard Process for Data Mining
- Algoritmos en minería de datos
- Secuencia
Data Sci
"Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation".
Macrodatos: Big data
Cuando hablamos de Big Data nos referimos a conjuntos de datos o combinaciones de conjuntos de datos cuyo tamaño (volumen), complejidad (variabilidad) y velocidad de crecimiento (velocidad) dificultan su captura, gestión, procesamiento o análisis mediante tecnologías y herramientas convencionales, tales como bases de datos relacionales y estadísticas convencionales o paquetes de visualización, dentro del tiempo necesario para que sean útiles.
Los macrodatos, también llamados datos masivos, inteligencia de datos, datos a gran escala o big data, es un término que hace referencia a conjuntos de datos tan grandes y complejos que precisan de aplicaciones informáticas no tradicionales de procesamiento de datos para tratarlos adecuadamente.
Con big data no se puede utilizar el enfoque estándar para analizar los datos, el análisis de datos permite observar tendencias.
El uso moderno del término big data tiende a referirse al análisis del comportamiento del usuario, extrayendo valor de los datos almacenados, y formulando predicciones a través de los patrones observados.
Características
- Volumen. Datos a gran escala, gran cantidad de datos, macrodatos.
La característica del volumen dificulta almacenar datos en un solo disco.
Como resultado, el almacenamiento distribuido (almacenar datos en más de una computadora) se ha convertido en una necesidad. - Velocidad
de extracción y procesamiento de la información de los datos. Qué sea oportuna.
Los datos llegan y se transmiten rápido. Se trata de la tasa de cambios, de vincular conjuntos de datos que vienen con diferentes velocidades y de ráfagas de actividades, en lugar de un ritmo constante habitual. - Variedad (complejidad). Datos no estructurados, no ordenados, provienen de diferentes fuentes. formatos diferentes y especialmente no estructurados.
- Metas. Pueden evolucionar en direcciones inesperadas
- Localización. Pueden estar los datos distribuidos en varios archivos y varios servidores en distintas geolocalizaciones
- Estructura. Pueden no ser estructurados, tener muchos formatos y vinculados a otros recursos
- Preparación. Un grupo de personas prepara los datos, otro grupo los analiza y otro grupo los utiliza
- Longevidad. Los datos se siguen utilizando, tienen una vida útil más larga e incierta
- Mediciones. esto va en relación con la localización, se aplican los protocolos y conversiones necesarias
- Reproducibilidad. A pequeña escala se pueden reproducir en su totalidad si algo falla, en los macrodatos puede que no sea fácil o posible empezar de nuevo.
- Intereses. Costo alto
- Instrospección. Los datos se describen de una forma característica.
- Análisis. Es posible que se tenga que recurrir a la extracción, revisión, reducción, normalización y la transformación, entre otros pasos, para abordar una parte de los datos cada vez y hacerlos más manejables
Veracidad. comprobar la calidad de datos.
Diferencias con los datos a pequeña escala
- Recolectar datos
- Analizar datos
- Visualizar datos
- Tomar decisiones
- Evaluar la estrategia (proceso de mejora)
- Data scientist / Científico de datos
- Data analyst / Analista de datos
- Data strategist / Estratega de datos
Data mining / Minería de datos
Conjunto de técnicas y procesos que permiten explotar y extraer cierto valor eliminando lo que no es de interés en el estudio para entender y encontrar patrones en los datos.
Se centra en el análisis para conocer el pasado, entender el presente para poder predecir el futuro.
Saca provecho del big data.
Fase avanzada de lo que engloba el big data
- Establecer el objetivo
- Pre procesamiento de datos
- Determinar el modelo
- Análisis de resultados
Web mining
Entender el patrón de comportamiento en la web
Text mining
Análisis y categorización de textos
Método descriptivo
Usar la minería de datos para conocer el pasado, entender el presente.
Objetivo. Describir lo que se recolecta
Clusterización. Establace grupos dentro de la misma data.
Método predictivo
Usar la minería de datos para intentar saber lo que pasará o predecir el futuro.
Técnica de regresión para basarnos en los datos actuales y hacer predicción sobre el futuro.
Transformación digital
- Cambio en la forma de trabajar y organizarse una empresa
- Incorporación de tecnologia que agilice y haga más eficiente la forma de trabajar
- Cambio incluso en la forma de entener la empresa
THE DATA SCIENCE VENN DIAGRAM
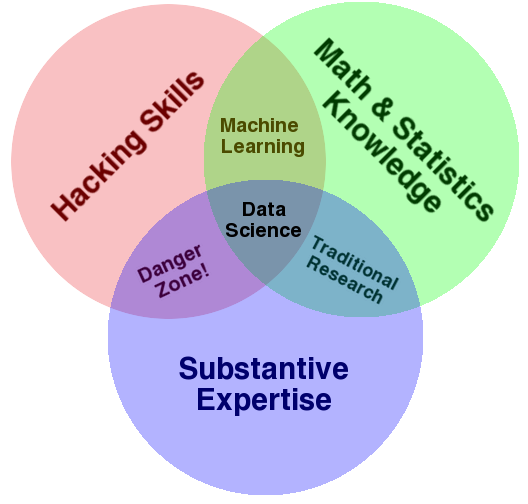
Analyzing the Analyzers
An Introspective Survey of Data Scientists and Their Work
Las tres facetas de la ciencia de datos son el conocimiento de campo, la programación y la estadística.
Machine Learning - Aprendizaje automático
Subcampo de las ciencias de la computación y una rama de la inteligencia artificial basado en estadísticas. , cuyo objetivo es desarrollar técnicas que permitan que las máquinas aprendan cómo completar tareas sin estar programadas explícitamente para hacerlo..
Un programa de computadora aprende a adaptarse a la información nueva que recibe.
Esencialmente, con el aprendizaje automático, utilizamos los datos existentes para aprender una función que puede hacer una predicción con nuevos datos.
Ejemplos:
Clasificación se utiliza para tomar una decisión o una predicción que involucra dos o más categorías o resultados.
Regresión donde se intenta predecir un resultado numérico basado en una o más variables de entrada.
Agrupación. En cada grupo tenemos objetos similares según sea su comportamiento.
Detección de anomalías. donde encontramos observaciones en los datos que se comportan diferente a la mayoría de la muestra, lo que llamaríamos los datos normales.
¿En Machine Learning que tareas se hacen?
- Seleccionar un modelo.
- Entrenar el modelo.
- Entrenados los modelos, se miden.
- Se evalúan los modelos.
Deep Learning - Aprendizaje profundo
Es una forma de aprendizaje automático que acumula múltiples capas de modelos de aprendizaje automático, uno encima del otro para formar una jerarquía.
Las redes neuronales profundas son, significativamente, más potentes y precisas en su detección de patrones, toma de decisiones y precisión de predicción que la generación anterior de algoritmos de aprendizaje automático.
Ejemplos: Reconocimiento de voz, generación de imagenes, etc.
IoT - Internet of Things
El internet de las cosas es la tendencia emergente de conectar todos los dispositivos, que son cosas, a través de internet.
También es una tendencia de conectar sensores que monitorean objetos físicos, que también son cosas.
Internet de las cosas está siendo impulsado por la economía, también está obteniendo un valor adicional de la extracción de los datos.
Como resultado, siempre que el valor derivado de los datos de un dispositivo sea mayor que el costo para conectar el dispositivo a internet, habrá un caso de negocio para habilitar internet en el dispositivo.
IoT. Internet de las cosas. Sensores inteligentes.
Anonimización de los datos
Convertir los datos en anónimos eliminando identificadores como nombres, direcciones y otra información personal identificativa obvia
Anonimato significa que los individuos no pueden ser identificados
Reidentificación o anonimización de datos es la práctica de hacer coincidir datos anónimos (también conocidos como desidentificación de datos) con información disponible públicamente, o datos auxiliares, con el fin de descubrir a la persona a la que pertenecen los datos. Esto es motivo de preocupación porque las empresas con políticas de privacidad, proveedores de atención médica e instituciones financieras pueden divulgar los datos que recopilan después de que los datos hayan pasado por el proceso de desidentificación (de-identification).
Confidencialidad significa que, independientemente de si los individuos pueden identificarse con los datos, sus datos no se compartirán con otras personas que no tienen permiso para verlos.
La confidencialidad es una cuestión de confianza que posibilita las interacciones.
La privacidad puede ser definida como el ámbito de la vida personal de un individuo, quien se desarrolla en un espacio reservado, el cual tiene como propósito principal mantenerse confidencial. También se aplica a la cualidad de privado.
Anonimizar los datos, eliminar identificadores y otros datos obvios de información de identificación personal para garantizar la privacidad.
La Confidencialidad de lo que se denomina Información no pública. La confidencialidad es un tema de confianza. La confianza, a su vez, garantiza la interacción, quién puede ver qué.
Datos generados por humanos
Datos intencionados
Son aquellos que sabes que estás creando y son tipos de datos que no existen hasta que la persona, deliberadamente, hace que ocurran, así que son registros de actos humanos.
- Fotos, video, audio
- Clics
- Búsquedas web
- Correos electrónicos, mensajes de texto
- Marcadores en libros electrónicos
- Compras en línea
Los metadatos, literalmente son datos «sobre datos», son datos que describen otros datos.
En general, un grupo de metadatos se refiere a un grupo de datos que describen el contenido informativo de un objeto al que se denomina recurso.
El concepto de metadatos es análogo al uso de índices para localizar objetos en vez de datos.
Con más relevancia para el mundo del big data, los metadatos, al ser generados por computadora, ya son legibles y consultables de forma digital.
Un ejemplo es una fotografía generada por un teléfono inteligente o camara digital, no simplemente un archivo digital en algún formato, sino los datos adicionales que el dispositivo puede brindar, como el tamaño en ancho y alto, el tamaño en bytes (por cierto las imagenes no tienen peso tienen tamaño), ubicación dónde fue tomada (GPS), fecha de creación y demás metadatos que se brinden respecto a la imagen.
Otro ejemplo son los correos electrónicos, sus metadatos podrian ser: remitente, destinarario(s) ya sea que estén en copia o en copia oculta (podría ser el metadato más relevante), y la feca en que se envió
Datos generados por máquinas
El 95% de los datos del mundo jamás serán vistos por humanos.
Estos datos invisibles se llaman datos M2M o datos «de máquina a máquina».
SQL - 1970
En 1970, E. F. Codd propone el modelo relacional y asociado a este un sublenguaje de acceso a los datos basado en el cálculo de predicados. Basándose en estas ideas, los laboratorios de IBM definieron el lenguaje SEQUEL (Structured English Query Language) que más tarde fue ampliamente implementado por el sistema de gestión de bases de datos (SGBD) experimental System R, desarrollado en 1977 también por IBM. Sin embargo, fue Oracle quien lo introdujo por primera vez en 1979 en un producto comercial.
SQL (por sus siglas en inglés Structured Query Language; en español lenguaje de consulta estructurada) es un lenguaje de dominio específico utilizado en programación, diseñado para administrar, y recuperar información de sistemas de gestión de bases de datos relacionales.
Una de sus principales características es el manejo del álgebra y el cálculo relacional para efectuar consultas con el fin de recuperar, de forma sencilla, información de bases de datos, así como realizar cambios en ellas.
Datos Estructurados
Tienen un orden establecido y un formato coherente o específico.
Los datos estructurados pueden almacenarse en una base de datos relacional (RDBMS)
Pueden ser almacenados y visualizados en renglones (o filas que es el grupo de celdas que se encuentran en forma horizontal ) y columnas (es una selección vertical de celdas).
Cada fila o renglón tiene que tener el mismo formato. Esta estructura se llama «modelo de datos».
Los datos estructurados se basan en el modelo de datos.
Un modelo de datos es parecido a los esquemas de una base de datos relacional, salvo que el esquema acaba definiendo toda la estructura de la base de datos.
Un esquema te muestra cómo organizar tu base de datos relacional. Incluye la tabla, las relaciones y las interconexiones que existen.
Un modelo de datos define la estructura de los campos individuales. Es la forma de definir lo que cabe en cada campo de datos. Aquí se decide si el campo tendrá texto, números o fechas.
Los datos estructurados son mucho más fáciles de digerir para los programas de Big Data, mientras que la miríada de formatos de datos no estructurados crea un desafío mayor. Sin embargo, ambos tipos de datos juegan un papel clave en el análisis de datos efectivo.
Los datos estructurados generalmente residen en bases de datos relacionales (RDBMS). Los campos almacenan números de teléfono de datos, números de seguro social o códigos postales delimitados por longitud. Incluso las cadenas de texto de longitud variable, como los nombres, están contenidas en los registros, lo que facilita la búsqueda. Los datos pueden ser generados por humanos o máquinas siempre que se creen dentro de una estructura RDBMS. Este formato se puede buscar eminentemente tanto con consultas generadas por humanos como mediante algoritmos que utilizan tipos de datos y nombres de campos, como alfabéticos o numéricos, moneda o fecha.
Las aplicaciones comunes de bases de datos relacionales con datos estructurados incluyen sistemas de reserva de aerolíneas, control de inventario, transacciones de ventas y actividad de cajeros automáticos. El lenguaje de consulta estructurado (SQL) permite realizar consultas sobre este tipo de datos estructurados en bases de datos relacionales.
Algunas bases de datos relacionales almacenan o apuntan a datos no estructurados, como aplicaciones de gestión de relaciones con los clientes (CRM). La integración puede resultar complicada en el mejor de los casos, ya que los campos de notas no se prestan a las consultas de bases de datos tradicionales. Aún así, la mayoría de los datos de CRM están estructurados.
Datos No Estructurados
Los datos no estructurados son esencialmente todo lo demás. Los datos no estructurados tienen una estructura interna pero no están estructurados a través de esquemas o modelos de datos predefinidos.
Carecen de esquema. El esquema es como el mapa que muestra los campos de datos, las tablas y las relaciones.
No hay un modelo de datos establecido.
Los datos no estructurados son un recurso en crecimiento constante.
Puede ser textual o no textual y generado por humanos o máquinas. También se puede almacenar en una base de datos no relacional como NoSQL.
Datos Semiestructurados
Tienen una parte de estructura que depende de la fuente, pero existe flexibilidad para cambiar los nombres de los campos.
Son datos que no están en campos fijos. No tenemos las filas y columnas de una hoja de cálculo, pero los campos están marcados y los datos son identificables.
Formatos más comunes de datos semiestructurados:
- XML (de Lenguaje de Marcado Extensible) y
- JSON o JavaScript Object Notation (de notación de objeto de JavaScript).
En informática, NoSQL es una amplia clase de sistemas de gestión de bases de datos que difieren del modelo clásico de SGBDR en aspectos importantes, siendo el más destacado que no usan SQL como lenguaje principal de consultas
La base de datos NoSQL más común es MongoDB, que utiliza JSON.
Por otra parte, si nos fijamos en el volumen, como Hadoop es una base de datos NoSQL y casi todo el big data está instalado en Hadoop o una base de datos Mongo.
Uno de los mayores problemas es que mientras las bases de datos SQL utilizan al menos versiones relativamente estandarizadas del lenguaje SQL query, no hay un lenguaje query estandarizado para las bases de datos NoSQL.
Almacenamiento distribuido
Almacenar datos en más de una computadora.
El almacenamiento de información también incluye el código de corrección de errores, que se utiliza para verificar su integridad.
Almacenamiento en la nube o internet
El espacio de almacenamiento es escalable, es decir, se solicita a demanda.
El almacenamiento de datos en la nube tiene mucho que ver con Big Data. La transformación ocurre en tiempo real, la capacidad de respuesta es inmediata, las comunicaciones facilitan que cada vez se pueda disponer de más datos.
Cómputo en la nube
Servicios informáticos prestados a través de internet en lugar de una computadora propia o personal.
Servicios:
- IaaS. Infraestructura como servicio.
La infraestructura como servicio es una versión online del hardware físico de una computadora, por eso a veces se la llama hardware como servicio.
Lo que hace posible la IaaS es la virtualización, un software que permite que una computadora ejecute varios sistemas operativos simultáneamente, como Windows y Linux en un Mac. Esto se llama máquina virtual. - PaaS. Plataforma como servicio.
Puede considerarse el estrato de desarrollo de software, porque es algo que usan los desarrolladores para generar aplicaciones que ejecutan en internet.
PaaS incluye la capa intermedia del software, como el sistema operativo, y otros componentes como el tiempo de ejecución. PaaS también da acceso a bases de datos - SaaS. Software como servicio.
Es la capa superior para la mayoría. Puede considerarse el estrato del consumidor de esta computación. Incluye aplicaciones web que se ejecutan totalmente a través del navegador - DaaS. Datos como servicio.
Es la última capa de la cómputo en la nube. Los datos como servicios son un servicio online como los demás, excepto que, en lugar de proporcionar acceso online a hardware de computación, sistemas operativos o aplicaciones, lo hace a los datos. Por este motivo, los proveedores de DaaS son similares a lo que llamamos almacenes de datos o «data marts». La idea es que los proveedores de DaaS puedan suministrar servicios al permitir que los clientes obtengan acceso a los datos de forma rápida y barata, garantizando la calidad de los datos.
GIGO
Examine los datos.
En informática, basura entra, basura sale (GIGO garbage in, garbage out) es el concepto de que los datos de entrada defectuosos o sin sentido producen una salida sin sentido o "basura".
El principio también se aplica de manera más general a todo análisis y lógica, en el sentido de que los argumentos no son sólidos si sus premisas son defectuosas.
Problemas en la calidad de los datos
- Registros de datos incompletos o corruptos
- Registros duplicados
- Errores tipográficos en el texto o los números
- Datos sin contexto o sin información sobre las unidades de medida
- Transformaciones incompletas de datos
- Cualitativamente es mucho peor. Falta de métodos para comprobar la precisión de los datos, porque puede ser que la persona que los recopiló no es la misma que los analiza o los presenta.
- Si los datos no se extraen, si no se convierten, puede que no se examinen, y es posible que un espacio se pierda o no se aproveche.
ETL
ETL Extract, Transform y Load (extraer, transformar y cargar).
Los datos tienen que extraerse del repositorio, si es necesario se realizan conversiones al formato apropiado para su análisis, así los datos son transformados, después podrán ser usados (cargados) en otras herramientas.
Un ETL se dedica a realizar labores de conexión a datos externos, transformación, limpieza y carga en el repositorio destino.
Podemos obtener datos desde muchas fuentes diferentes habituales, como las bases de datos relacionales, los Data Warehouse, Data Lakes, Cubos OLAP, pero también podemos obtener datos de los archivos de registros, las Bases de datos NoSQL, las API REST, y en la nube Internet, sensores de muchos tipos y otros dispositivos inteligentes.
Seguimiento y detección de anomalías
El big data puede servir para saber cuándo ocurren hechos inusuales o cuándo están a punto de ocurrir.
Seguimiento
El seguimiento puede ser muy útil cuando sabes lo que buscas y necesitas una notificación cuando pasa.
El seguimiento es una tarea específica. Sabes lo que buscas, esperas que ocurra, y si es posible, se da una respuesta automática.
Detecta eventos concretos y necesita de criterios expecíficos para desencadenar el evento.
Anomalías
Saber si pasa algo inusual, necesita basarse en criterios flexibles, puede ser una combinación de varios factores diferentes.
Los criterios flexibles suelen existir para atraer la atención hacia algo.
Una detección de anomalías puede percibir patrones
Lo que el big data aporta es la posibilidad de buscar eventos o combinaciones de factores extremadamente raros.
Análisis de texto
La minería de datos utiliza procedimientos estadísticos para encontrar patrones inesperados en los datos, identifica asociaciones, agrupa personas y casos.
Para tener la capacidad de adaptar los servicios a las preferencias y la conducta de cada individuo, una vez recopilados los datos suficientes.
Se centra en el contenido
Las aplicaciones de la minería de texto son análisis de opiniones determinar lo que la gente cree sobre algo, polaridad determinar si algo es positivo o negativo.
Análisis predictivo
Técnicas que se adaptan para trabajar con big data e intentar predecir eventos futuros sobre la base de observaciones del pasado.
El big data permite mejorar las predicciones.
Visualización - ¿Qué dicen los datos?
La visualización permite extraer conocimiento de grandes volúmenes de datos, permite dar sentido a la estructura y patrones subyacentes que puedan existir en los datos.
El objetivo de la visualización y la representación de los datos en gráficos es informar.
Obtener una visión completa de nuestro escenario y descubrir el valor de los datos.
Para interpretar la información de manera rápida y clara, y cualquier factor que distraiga y dé una impresión equivocada es un error y debería eliminarse.
La visualización de datos es un área donde los humanos contribuyen en el análisis del big data, y las computadoras aportan todos los modelos conocidos.
La visualización de datos es dar a conocer el dato en una representación visual idonea como: mapa de calor, texturas y colores, animaciones, movimiento o incluso, interactividad, cuadros, tablas, gráficos, mapas, todo junto, con la finalidad de lograr un mejor entendimiento de escenarios de datos que necesitamos representar y explicar al destinatario.
Necesitamos visualizar los datos para poder explorar, comprender y explicar completamente los datos, este es el verdadero poder de la visualización de datos.
Las expresiones enla visualización de los datos son de:
- Comparación
- Relación
- Distribución
- Composición y
- Representación
Es importante encontrar la forma en que se distribuyen los datos para encontrar en estos patrones y anomalías.
Puntos a tener en cuenta en la visualización de datos:
- Saber lo que realmente se quiere decir
- Saber qué están diciendo los datos
- Saber que es lo que la audiencia necesita escuchar
Es muy importante saber cómo presentar los datos para que tengan sentido y dirigidos a una audiencia específica.
Crear jerarquías de información puede ayudar a presentar datos respondiendo a las preguntas:
- ¿Qué?
- ¿Por qué?
- ¿Quién?
- ¿Cuándo?
- ¿Dónde?
- ¿Cómo?
Después hacer un refinamiento y elaborar nuevas preguntas para completar lo que sea necesario.
El área de visualización de datos, tiene la misión de mostrar, de manera gráfica y clara, los resultados obtenidos en un proyecto.
¿Qué necesita conocer de la audiencia para la visualización
- Cultura
- Experiencia
- Lenguaje
- Perspectiva
- Contexto
- Jerarquía
- Funcíon
Las visualizaciones de datos hacen posible la narración de historias.
Conocer los datos a visualizar
Comprobar que los datos contienen todo lo que tenga sentido para lo que deseamos transmitir. Contar con un modelo de datos. Es obligatorio entender los datos para poder visualizarlos y conocer los datos suficientemente bien como para detectar errores, ausencias y anomalías en ellos.
El profundo conocimiento de los datos permitirá definir cómo se deben mostrar.
Descubrimientos en los datos
Comprender qué técnicas utilizar para descubrir ideas o patrones para la obtención de los resultados deseados.
Explorar es la forma de profundizar en los datos para poder encontrar patrones y valores atípicos.
Simplificación en los datos
Manipulación de los datos según convenga:
Transposición, cambiar la posición de vertical a horizontal o viceversa, para crear estructuras más sencillas que se ajusten mejor al modelo de datos que se necesita analizar.
Presentación, espaciado, redundancia, formato.
Fomato de datos, número de decimales, fechas, moneda
Tener en cuenta la agregación, clasificación y filtrado de los datos.
Tipos de datos
Duración, fecha y hora.
Métricas, númericos, unidades, decimales, precisión, magnitud
Estados, verdadero, falso (booleano)
Cuantitavivos, discretos, continuos
Categoricos, agrupaciones ordinales o nominales.
Inteligencia de negocios o empresarial - Business intelligence
Analítica de datos aplicada a los negocios.
Conjunto de sistemas de software que apoyan a a la toma de decisiones de negocio, basados en la recogida de análisis de hechos o datos.
Se denomina inteligencia empresarial, inteligencia de negocios, inteligencia comercial o BI (del inglés business intelligence), al conjunto de estrategias, aplicaciones, datos, productos, tecnologías y arquitectura técnicas, los cuales están enfocados a la administración y creación de conocimiento sobre el medio, a través del análisis de los datos existentes en una organización o empresa.
El término inteligencia empresarial se refiere al uso de datos en una empresa para facilitar la toma de decisiones.
Abarca la comprensión del funcionamiento actual de la empresa, bien como la anticipación de acontecimientos futuros, con el objetivo de ofrecer conocimientos para respaldar las decisiones empresariales.
Las herramientas de inteligencia se basan en la utilización de un sistema de información de inteligencia que se forma con distintos datos extraídos de la producción, con información relacionada con la empresa o sus ámbitos, y con datos económicos.
Las herramientas de inteligencia analítica posibilitan el modelado de las representaciones basadas en consultas para crear un cuadro de mando integral que sirve de base para la presentación de informes
Gobierno de datos
Conjunto de prácticas que se realizan siempre, La función principal del gobierno de datos es desarrollar políticas y estándares.
La gobernanza de datos tiene que existir todo el tiempo.
Los dos roles del gobierno de datos más importantes son:
- Propietarios de datos
- Administradores de datos
Ciclo de vida de los datos
- Obtención y transformación de datos
Estrategia de obtención de datos propios y externos para implementar el gobierno de los datos, definir la administración de datos maestros, la arquitectura de datos empresariales y cómo podemos importarlos a nuestro modelo de datos empresariales. - Gestión y trabajo con datos
Ingeniería y administración, trabajar con los datos de varias formas para: organizarlos, persistirlos, asegurarlos, perfilarlos, transformarlos en un modelo que nos permita analizarlos.
Definición del sistema de administración de datos, ya sea en bases de datos relacionales o no, y el lenguaje de consulta que, en cada caso, se utilice. - Obtención de valor a partir de los datos
Inteligencia empresarial, análisis y modelado predictivo para conocer mejor nuestros datos e intentar predecir los resultados de decisiones basadas en patrones de datos existentes.
Modelo de datos
Modelamos para organizar y definir nuestros datos.
Describir la relación que existe entre elementos y la interacción que se produce en el proceso.
Cada elemento identificado en el proceso se convierte en una entidad como parte del proceso de modelado de datos.
Identificar distintos tipos de una misma entidad.
La definición del diccionario de datos de cada entidad es una de las tareas del programa del gobierno de datos.
Definición de transacciones.
Definición del modelo conceptual que no suele incluir atributos y tipos sino que tiene una descripción general de los requisitos de datos.
El modelador de datos toma ese modelo conceptual y los resultados son el modelo de datos lógico. Un modelo de datos lógico se suele representar como un diagrama entidad-relación.
El modelo lógico es más detallado que el modelo conceptual porque tiene los metadatos de la entidad.
Los metadatos que son los datos que describen otros datos son los atributos y dominios de datos que son tipos de datos para una entidad
Identificar reglas de negocio
Es en el modelo lógico donde se aplican técnicas de normalización.
Aprobado el modelo lógico por la empresa, se promueve al modelo físico.
El modelo físico es la representación más cercana a la base de datos real.
En el modelo físico las entidades se denominan tablas y los atributos se denominan columnas.
Conocimiento del cliente
El desafío, desde el punto de vista del tratamiento de datos, no es solo conocer al cliente, sino enfocarse en el cliente y activar todos los procesos necesarios para su retención.
Obtener todos los datos que son necesarios para analizar la gestión empresarial propia, la del entorno competitivo y la del cliente.
Poner todos esos datos en valor, convertir los datos en información y la información en conocimiento para poder tomar las decisiones más acertadas, y medir el impacto en el negocio.
Análisis exploratorio y estadístico
Se puede realizar mediante:
-
Aprendizaje supervisado, se dividen los datos de muestra
en un conjunto de datos de entrenamiento y un conjunto de datos de prueba.
El conjunto de datos de entrenamiento se utiliza mientras se desarrolla el modelo y el conjunto de datos de prueba se utiliza posteriormente para validar la efectividad del modelo. -
Aprendizaje no supervisado,
en el que no existe un conjunto de datos de entrenamiento o prueba.
Este modo de aprendizaje será el más adecuado en escenarios de detección de anomalías o algún tipo de agrupamiento.
Ciencia de datos
Campo interdisciplinario compuestos por ciencias de la computación o informática, matemáticas, estadísticas, principalmente.
El objetivo de la ciencia de datos es transformar los datos en conocimiento, conocimiento que puede usarse para tomar decisiones racionales.
Proceso de ciencia de datos
- Preguntar que queremos contestar, esto es una hipótesis que queremos probar, una decisión que queremos tomar o algo que queremos intentar predecir.
- Recopilar datos para el análisis, esto significa diseñar un experimento para crear nuevos datos o los datos ya existen y solo se necesita encontrarlos.
- Preparar datos para el análisis, esto es limpiar y transformar estos datos para convertirlos en una forma adecuada para el análisis.
- Crear un modelo para los datos, este puede ser un modelo numérico, un modelo visual, un modelo estadístico o un modelo de aprendizaje automático. Utilizamos este modelo para proporcionar evidencia a favor o en contra de nuestra hipótesis para ayudarnos a tomar una decisión o para predecir un resultado.
- Evaluamos el modelo, determinar si el modelo responde a la pregunta, ayuda a tomar una decisión o crea una predicción precisa. Además, debemos asegurarnos de que nuestro modelo sea apropiado para los datos.
Los datos no son el producto, es lo que se pueden entender con ellos.
Una colección enorme de datos no hace a un equipo de data science. Lo que lo constituye son las preguntas que sepa hacer. El método científico es lo que lo distingue.
Mostrar los valores en los datos
La manera en que presenta la información es importante:
- Posición
Las reglas de negocio indicarán cómo debe colocarse la información para denotar énfasis. - Tamaño
El tamaño depende de su valor. - Color
El color sirve para obtener atención, agrega interés visual, por lo que debe considerar como emplear los colores. Una de las funciones del color es garantizar el contraste. - Contraste
Otra forma de obtener atención, el uso del contraste es una excelente forma de mostrar las variaciones en los datos. - Forma y Escala
Para una representación realmente válida y precisa de los datos.
Resaltar contribuye a mostrar la variación
Use etiquetas y leyendas en justa medida, es decir, las necesarias, no etiquete todo, solo lo que es importante.
Ofrezca filtros categoricos.
La tipografía si importa, tipo de fuente, tamaño y espaciado como guía hacia los datos, sirven para distinguir entre elementos.
La interactividad permite la exploración.
Los elementos visuales, la ilustración y la iconografía, contribuyen a la conexión de la audiencia con el contenido que se muestra. Tome en cuenta que es un complemento.
¿Qué gráfico usar?
Necesitamos saber distinguir entre las categorías de gráficos: comparaciones, tendencias, proporciones, gráficos geográficos, relaciones, distribución y evolución
Gráfico de barras
El área de las barras sirve para establecer comparaciones.
Buenas prácticas: Si se utiliza con una dimensión no debemos emplear tonos, sombras ni degradados de color.
Gráfico de línea se utiliza para mostrar los cambios que se producen en los indicadores a lo largo del tiempo.
Gráfico de área es como un gráfico de líneas relleno, un gráfico de área muestra la relación en el tiempo, y también puede visualizar el volumen, sus dos variantes son: Los gráficos de barras apiladas comparan el valor relativo, y los gráficos de barras agrupadas comparan elementos de una misma categoría. Muestran el desglose porcentual que tiene cada elemento de una categoría.
Los gráficos de área sirven para mostrar la distribución de los datos; si se trata de un indicador o medida, lo mejor es utilizar un histograma, que es un tipo de gráfico de barras modificado que categoriza cada uno de los valores en un cierto número de contenedores y luego los cuenta.
Comparaciones gráfico de barras o columnas.
Tendencias valores que cambian en el tiempo, gráfico de líneas.
Proporciones o la parte del todo, gráficos circulares o gráficos de barras apiladas.
Gráficos geográficos cuando los datos tienen un componente espacial, trabajamos con mapas.
Gráfico de dispersión es ideal para mostrar la correlación entre dos variables, porque permite destacar los valores atípicos. En estos gráficos se suele trabajar con más atributos, como tamaño, color y forma para analizar una tercera medida y para crear distinción en los datos.
Gráficos de burbujas son como los gráficos de dispersión, con la ventaja de que se puede utilizar una tercera variable. Los gráficos de burbujas de tamaño, utilizan el tamaño del círculo para representar el valor
Gráfico circular es bastante efectivo para comparar la diferencia entre dos puntos de datos y especialmente, si es solo una variable. No es adecuado en caso de que haya muchos elementos dentro de una misma categoría. Sirven cuando estés tratando de mostrar una parte o partes de un todo.
Relaciones entre datos cuando queremos expresar correlación, jerarquía, redes y flujos o conexiones entre varios valores.
Para identificar la correlación existente entre dos indicadores o métricas, utilizamos el diagrama de dispersión.
Es de utilidad trabajar con el organigrama o diagrama de árbol, para analizar relaciones de jerarquías entre los datos.
Evolución cuando el foco del análisis está en la variación de los datos desde un punto de partida, que con mucha frecuencia es cero, hasta el final.
Visualización dinámica con un eje de tiempo que deje ver los movimientos que se han producido en los indicadores, según ha ido pasando el tiempo.
Distribución de los datos.
Histograma para mostrar la distribución de valores a lo largo del tiempo. Representación en la que puede apreciarse si las medidas tienden a estar centradas o a dispersarse ya que la superficie de cada barra es proporcional a la frecuencia de los valores representados.
Gráfico de cajas
para mostrar variedad de datos, qué tan grande es el grupo, cómo se distribuye la muestra, cuál es el valor de la mediana y los cuartiles superior o inferior. Desvela la presencia de valores atípicos, mostrando a la vez el promedio y los valores extremos.
Gráfico de puntos
para descubrir la distribución de los datos y mostrar todos los puntos, individualmente
Gráfico de pirámides
gráficos de barras agrupadas que permiten comparar dos variables simultáneamente de forma consecutiva.
La selección de gráficos se basa en saber qué gráficos existen, cual es la función de cada uno de ellos y elegir el gráfico dependerá de lo que mejor se adapte para comunicar todo lo que se necesite de los datos..
Composición, distribución y correlación de los datos
El análisis de las relaciones en un conjunto de datos, nos permite buscar patrones en grupos.
Gráfico circular para la composición de un conjunto de datos.
Gráficos circulares para mostrar una parte o partes de un todo, en algunos casos puede que sea mejor el gráfico de anillos que cumple los mismos objetivos con una estética diferente.
Diagrama de dispersión se utiliza para identificar el grado de correlación entre dos o más métricas o indicadores.
Diagrama de Venn consiste en dos o más áreas circulares que representan conjuntos que comparten elementos comunes sitúados en la intersección de los círculos, es posible representar las relaciones de intersección, inclusión o excepción relativa de los conjuntos entre las cosas.
Diagrama jerárquico clásico para conocer los niveles de jerarquía que existen entre los elementos.
Diagrama o mapa de árbol ideal para crear interactividad, y permitir ascender y descender por los distintos niveles de jerarquía.
Gráficos de reglas de asociación sirven para revelar la asociación que existe entre elemento específicos.
Diagrama de flujo El tipo de relación que se produce en un flujo, se parece a la que se produce en una jerarquía, pero, generalmente, indica una relación basada en el tiempo, o al menos, en la causa y el efecto. Es muy eficiente para mostrar el comportamiento de unos datos a través de etapas, tareas o puntos específicos
Diagrama de Gantt para obtener información sobre la duración de procesos. Compuesto de al menos tres elementos: la dimensión por la que queremos dividir los datos, fecha de inicio y duración.
Gráficos de radares o arañas son buenos para mostrar múltiples variables a la vez, y mostrar sus fortalezas relativas entre los elementos.
Mapa de marcadores o de puntos Es el clásico mapa con señalizaciones de puntos de interés.
Mapas de calor o de densidad permite observar datos subdivididos por categoría, donde podemos encontrar patrones en esos datos.
Mapa de símbolos funciona colocando una marca en el centro de cada uno de los puntos geográficos que se estan analizando.
Mapa de flujos se utilizan para ver los desplazamientos entre regiones o puntos en el mapa.
Mapas isopleta para representar cantidades de lluvia o concentraciones de calor.
Minigráficos o sparklines son gráficos de alto nivel y poco detalle, es una vista condensada de los datos. Reduce la cantidad de detalle que se muestra, por lo que solo se mostrarán los valores atípicos y los eventos significativos.
Visualización Vs. Historia
Visualización no es lo mismo que contar una historia.
La visualización de datos va de la mano de una narrativa contundente.
Las herramientas de narración no son lo mismo que la narración.
La narración debe conectar, lograr que la audiencia encuentre el significado.
Recursos narrativos: para atraer al público.
- Anécdotas, relato breve personal relacionado con el caso.
- Estudios de caso, posibles problemas y soluciones
- Ejemplos
- Panoramas, casos hipotéticos en tercera persona, que estimulan el pensamiento
- Viñetas, escena breve narrada en tercera persona
- Principio, trata sobre el contexto: Actores y situaciones
- Nudo, indica un conflicto: Problema o argumento y se implica a la audiencia fomentando la imaginación
- Desenlace, solución: acciones que se emprendieron
Un conflicto es de más ayuda para encontrar el sentido e implicar al público.
El final de la historia debería crear acción.
Si existe un argumento y un conflicto, el público conecta con la historia.
El conflicto atrae la atención del público. Una vez conseguido, es importante mantener el dinamismo de la historia. Una forma efectiva es añadir detalles a cada parte de la historia. Estos detalles funcionan como notas mentales para recordar el conflicto mayor.
Con los detalles se atrae más al público, porque se hacen una imagen mental mientras la oyen. Ayudan al público a conectar con el argumento y el conflicto. Incluir detalles es útil porque pueden ser memorables y dan continuidad.
Exponer no es lo mismo que narrar
Conoce a tu público para lograr conectar con el.
Cree tu historia.
La historia tiene argumento, personajes y conflictos.
El valor está en la historia que narre el presentador, si comienza con una historia, no hace falta poner énfasis en los datos, ya que no valen nada a menos que se conecten con el público. Los datos aislados no lo consiguen, es la historia acerca de los datos la que te ayudará a conectar con un sentido.
Una historia sirve para que el público conecte los datos con el significado de lo que se quiere comunicar.
No reemplace una historia interesante con una visualización atractiva.
Una buena sesión narrativa pone los datos en segundo plano.
Elimine de la historia todo lo que no sea esencial.
Ha eliminado las distracciones y se ha centrado en lo que tiene valor.
Explicar los datos de manera resumida y elimine texto innecesario.
Metáforas
Conectan algo conocido con algo desconocido. Hacen que lo distante parezca más familiar.
Si comparas dos elementos diferentes, es una metáfora.
Visión
Establece una visión, los contrastes son la habilidad de separar el contexto presente de la visión de futuro.
Enfoque EVA, implicación, visión y autenticidad para aumentar tu propia credibilidad
Para plantear una visión, necesitas que el público se implique.
La visión es la parte de la historia con más efecto.
Para que una visión sea creíble, debe ser auténtica
Visión. idea que contrasta el presente con un futuro potencial.
Motivación
Motiva al público:
- Conocer al público, descubrir que los motiva y determinar sus necesidades.
- Crear una conexión emocional, emplear anécdotas personales.
- Poner todo en contexto, tratar de explicar el por qué.
- Conseguir que el público se implique, lograr el interés en los personajes y argumento.
- Usar metáforas, intentar que el cambio parezca conocido, para facilitar la novedad.
- Acción, explicar con claridad que se espera que hagan, motivar el cambio
Errores
En ciencia de datos no se trata de comunicar los informes de situación, sino que se intenta descubrir alguna novedad.
Si la historia consiste solo en mostrar los datos, el público ignorará la presentación.
Una buena historia con datos se refuerza con visualizaciones.
No dependa demasiado de las visualizaciones de los datos.
Limita los datos que incluyes en la presentación.
Concéntrate en los elementos que el público pueda recordar.
Define las características clave de la historia, el argumento y el conflicto, y luego presenta los datos de forma atractiva.
Ciencia de datos
Historia
En
1962, John W. Tukey precedió al término “Ciencia de Datos” en su artículo “The Future of Data Analysis”
al explicar una evolución de la estadística matemática.
En este, definió por primera vez el análisis de datos como:
“Procedimientos para analizar datos, técnicas para interpretar los resultados de dichos procedimientos, formas de planificar la recopilación de datos para hacer su análisis más fácil, más preciso o acertado, y toda la maquinaria y los resultados de las estadísticas matemáticas que se aplican al análisis de datos.”
En
1977 publicó “Exploratory Data Analysis”,
argumentando que era necesario
poner más énfasis en el uso de datos para sugerir hipótesis que probar en modelos estadísticos.
La ciencia de datos usa el método científico con los datos que tienes.
La ciencia de datos es un campo interdisciplinario que involucra métodos científicos, procesos y sistemas para extraer conocimiento o un mejor entendimiento de datos en sus diferentes formas, ya sea estructurados o no estructurados, lo cual es una continuación de algunos campos de análisis de datos como la estadística, la minería de datos, el aprendizaje automático, y la analítica predictiva.
Es el método científico y no las herramientas lo que hace al científico de datos.
Las herramientas caben en tres categorías básicas:
- Almacenamiento (storing),
- Depuración y (scrubbing)
- Análisis (analyzing)
Los orígenes de SQL están ligados a las bases de datos relacionales, específicamente las que residían en máquinas IBM bajo el sistema de gestión System R, desarrollado por un grupo de la IBM en San José, California.
En
1970, E. F. Codd propone el modelo relacional y
asociado a este un sublenguaje de acceso a los datos basado en el cálculo de predicados.
Basándose en estas ideas, los laboratorios de IBM definieron el lenguaje SEQUEL (Structured English Query Language) que más tarde fue ampliamente implementado por el sistema de gestión de bases de datos (SGBD) experimental System R, desarrollado en
1977 también por IBM.
Sin embargo, fue Oracle quien lo introdujo por primera vez en
1979 en un producto comercial.
SQL (por sus siglas en inglés Structured Query Language; en español lenguaje de consulta estructurada) es un lenguaje de dominio específico utilizado en programación, diseñado para administrar, y recuperar información de sistemas de gestión de bases de datos relacionales.
Una de sus principales características es el
manejo del álgebra y el cálculo relacional
para efectuar consultas con el fin de recuperar, de forma sencilla, información de bases de datos,
así como realizar cambios en ellas.
Originalmente basado en el álgebra relacional y en el cálculo relacional, SQL consiste en:
- Un lenguaje de definición de datos,
- Un lenguaje de manipulación de datos y
- Un lenguaje de control de datos.
También el SQL a veces se describe como un lenguaje declarativo, también incluye elementos procesales.
SQL fue uno de los primeros lenguajes comerciales para el modelo relacional de Edgar Frank Codd como se describió en su artículo de investigación de
1970
El modelo relacional de datos para grandes bancos de datos compartidos.
A pesar de no adherirse totalmente al modelo relacional descrito por Codd, pasó a ser el lenguaje de base de datos más usado.
SQL pasó a ser el estándar del Instituto Nacional Estadounidense de Estándares (ANSI) en
1986 y de la Organización Internacional de Normalización (ISO) en 1987.
Los primeros ingenieros se esforzaron por aprender cuál era la forma más eficiente de agrupar las tablas. Crearon mapas que mostraban las relaciones entre tablas y los llamaron esquemas.
Hace falta tener muy clara la apariencia de la información antes de empezar a recogerla. Si te equivocas, el esfuerzo para corregir el diseño es muy costoso.
SQL es un lenguaje elegante que puede extraer datos de muchas tablas relacionales diferentes y es capaz de reconectar varias tablas y presentar los datos en una tabla virtual que se llama Vista.
Con los años, se añadieron muchas funciones a las bases de datos relacionales y se creó un sistema de gestión de bases de datos relacionales llamado RDBMS.
ETL - Extract, Transform and Load
Extract, Transform and Load («extraer, transformar y cargar», frecuentemente abreviado ETL) es el proceso que permite a las organizaciones mover datos desde múltiples fuentes, reformatearlos y limpiarlos, y cargarlos en otra base de datos, data mart, o data warehouse para analizar, o en otro sistema operacional para apoyar un proceso de negocio.
Los procesos ETL también se pueden utilizar para la integración con sistemas heredados. Se convirtieron en un concepto popular en los años
1970.
El sistema de gestión de bases de datos relacionales es la piedra angular de los datos corporativos.
Almacén de datos (EDW)
Un almacén de datos (del inglés data warehouse) es una colección de datos orientada a un determinado ámbito (empresa, organización, etc.), integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza.
Se usa para realizar informes (reports) y análisis de datos y se considera un componente fundamental de la inteligencia empresarial.
Se trata, sobre todo, de un expediente completo de una organización, más allá de la información transaccional y operacional, almacenado en una base de datos diseñada para favorecer el análisis y la divulgación eficiente de datos (especialmente OLAP, procesamiento analítico en línea).
El almacenamiento de los datos no debe usarse con datos de uso actual.
Los almacenes de datos contienen a menudo grandes cantidades de información que se subdividen a veces en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sea necesario.
Un almacén de datos o EDW es un tipo especial de base de datos relacional que se dedica a analizar la información.
Las bases de datos tradicionales están optimizadas para el procesamiento de transacciones en línea o OLTP.
Periódicamente, se importan datos al almacén de datos de los distintos sistemas de planeamiento de recursos de la entidad (ERP) y de otros sistemas de software relacionados con el negocio para la transformación posterior.
Es práctica común normalizar los datos antes de combinarlos en el almacén de datos mediante herramientas de extracción, transformación y carga (ETL).
Estas herramientas leen los datos primarios (a menudo bases de datos OLTP de un negocio), realizan el proceso de transformación al almacén de datos (filtración, adaptación, cambios de formato, etc.) y escriben en el almacén.
OLTP es la sigla en inglés de Procesamiento de Transacciones En Línea (OnLine Transaction Processing).
Es un tipo de procesamiento que facilita y administra aplicaciones transaccionales, usualmente para entrada de datos y recuperación y procesamiento de transacciones (gestor transaccional).
Las bases de datos tradicionales están optimizadas para el procesamiento de transacciones en línea o OLTP. Un almacén de datos se usa para el procesamiento analítico, conocido como OLAP.
NoSQL
Carlo Strozzi usó el término NoSQL en
1998 para referirse a su base de datos.
Era una base de datos open-source, ligera, que no ofrecía un interface SQL, pero sí seguía el modelo relacional (Strozzi sugiere que, ya que el actual movimiento NoSQL "Se sale completamente del modelo relacional, debería, por tanto, haberse llamado 'NoREL', o algo así.").
NoSQL (a veces llamado "no solo SQL") es una amplia clase de sistemas de gestión de bases de datos que difieren del modelo clásico de Sistema de Gestión de Bases de Datos Relacionales (SGBDR) en aspectos importantes, siendo el más destacado que no usan SQL como lenguaje principal de consultas.
Los datos almacenados no requieren estructuras fijas como tablas, normalmente no soportan operaciones JOIN, ni garantizan completamente atomicidad, consistencia, aislamiento y durabilidad (ACID) y habitualmente escalan bien horizontalmente.
Los sistemas NoSQL se denominan a veces "no solo SQL" para subrayar el hecho de que también pueden soportar lenguajes de consulta de tipo SQL.
Si una base de datos no es relacional, es más fácil cambiarla y usarla. No existe una gran diferencia entre el funcionamiento de tu aplicación web y la forma en la que almacenas los datos en la base.
No hace falta que pases por procesos agotadores de creación y división de las tablas existentes, para crear diferentes vistas. Esto se denomina «normalizar tu base de datos». Sin esquemas, no hace falta saber cómo será todo antes de comenzar.
Una base de datos NoSQL es apta para clústeres. Se pueden almacenar los datos en varios cientos o incluso miles de servidores de bases de datos. En una base de datos NoSQL, los registros se guardan en una transacción que se llama agregado, que contiene toda la información.
Macrodatos (Big data)
1997:
Se utiliza por primera vez el término ‘Big Data’.
Los investigadores de la NASA Michael Cox y David Ellsworth afirman en un artículo (en inglés) que el gran aumento de datos se estaba convirtiendo en un problema para los sistemas informáticos actuales. Esto se da a conocer como el “problema del Big Data”.
El problema del big data
La visualización ofrece un desafío interesante para los sistemas informáticos: los conjuntos de datos son generalmente bastante grandes, lo que pone a prueba las capacidades de la memoria principal, el disco local e incluso el disco remoto. A esto lo llamamos el problema del big data.
Se planteaban cosas como:
Los algoritmos utilizados para visualizar datos CFD incluyen líneas de flujo, líneas de trazos, trazas de partículas, búsqueda de núcleos de vórtice, así como planos de corte, isosuperficies e isosuperficies locales empleados en otros dominios de aplicación. La mayoría de estos son algoritmos locales que solo necesitan atravesar un subconjunto de los datos para calcular la geometría sintética para una visualización determinada. La mayoría de los sistemas de visualización CFD han admitido la visualización de flujos estables (cuadrícula única, entrada de solución única) (por ejemplo, [4, 5, 28]). Por lo general, estos han evitado el problema del big data al requerir que tanto la cuadrícula como la solución encajen completamente en la memoria principal antes de que comience la visualización.
Al menos un sistema admite la visualización de flujo inestable (múltiples cuadrículas, múltiples soluciones): el Kit de herramientas de análisis de flujo inestable (UFAT) [19]. Además de los desafíos algorítmicos que deben abordarse para visualizar el flujo a través de múltiples pasos de tiempo, los flujos inestables desafían al sistema informático con grandes cantidades de datos. Normalmente, el "solucionador" genera solo 1 de cada 10, o 1 de cada 100 de los pasos de tiempo debido a la capacidad limitada del sistema, el disco y el sistema de visualización. Pero incluso entonces, la salida puede tener cientos de pasos de tiempo, cada uno de los cuales puede superar hoy los 500 Mbytes.
En el dominio de la visualización, Song ha demostrado que el problema de los grandes datos se puede mitigar en un sistema de flujo de datos reduciendo la granularidad de los nodos de flujo de datos [25]. Para la visualización de datos de ciencias de la tierra, la biblioteca Common Data Format (CDF) [22] implementa una forma simple de segmentos paginados por demanda. En nuestra terminología, CDF asigna un segmento a cada archivo y solicita páginas de forma independiente para cada uno de estos segmentos. Dado que se asocia un caché con cada archivo, la memoria en uso crece con el número total de archivos abiertos. El control de la aplicación sobre este crecimiento es difícil a menos que la aplicación realice un seguimiento de sus propios patrones de acceso en los datos subyacentes. No tenemos conocimiento de estudios sobre CDF que exploren tamaños de página alternativos, políticas de reemplazo y almacenamiento y organización de datos, por lo que no podemos abordar las compensaciones en los segmentos de páginas de demanda para datos de ciencias de la tierra.
Limpieza de datos
Mantener los datos
Para la limpieza, profundice en los datos utilizando técnicas de: filtrado, agrupación, ordenado, para conocer los datos y por ejemplo podría comprobar si se tienen valores nulos.
- En algún momento podrías encontrar una pregunta para hacer que no conocías antes.
- Resulta barato mantener cantidades masivas de datos.
- Evitarse la difícil decisión de qué habría que eliminar.
- Se acumula demasiada basura en esos clústeres de big data. (Ruido en los datos)
- Cuanta más basura haya, más difícil será encontrar resultados interesantes. Si se decide mantener todo, se tendrá que trabajar más arduo a la hora de crear informes de interés. Hará falta más filtros y los datos tendrán más ruido.
Preparación de datos
Incluye la exploración, limpieza y configuración de los datos útiles para el proceso de minería de datos, así como conocer el tipo y cantidad de datos, si son valores discretos podría convenir agruparlos y tal vez conocer el número de casos para cada valor.
Valor atípico, aquel que esta fuera del intervalo esperado o es un valor ausente/faltante o sesga la distribución del modelo.
Eliminar valores atípicos, para su detección use análisis de patrones a los datos y determine si los distintos valores se corresponden con el compartamiento del resto del conjunto de datos.
Valores erroneos, indican la presencia de errores
¿Qué se tendría que hacer para resolver la preparación de datos?
- Detectar valore ausentes o faltantes
- Eliminar filas
- Reemplazar por un valor promedio
- Quitar los valores atípicos
- Manejo de etiquetas, ya sea cambiando o agregando a fin de que los datos sean más fáciles de leer y comprender
- Cambiar códigos numéricos por textos descriptivos
Estadística descriptiva
La estadística descriptiva es una herramienta de análisis. Un equipo de data science se dedica a:
- Recoger datos, depurarlos y almacenarlos.
- Luego formulan preguntas a partir de ellos.
- Crean informes mediante matemáticas para entender mejor esa información.
En el equipo de data science, siempre debes cuestionar las historias que se cuenten con estadísticas. Repasa siempre las justificaciones de cada afirmación. Intenta que los informes usen formas diferentes de describir los datos.
La correlación es una serie de relaciones estadísticas que miden el grado de relación entre dos variables.
Amazon y Netflix utilizan la correlación para la recomendación de sus peliculas, series y de sus productos.
Usualmente se mide entre uno y cero:
Si hay una correlación de uno, las dos variables se correlacionan con fuerza.
Si la correlación es de cero, las dos variables no tienen relación.
El uno también se puede expresar en positivo o negativo:
Un uno negativo es una inversa, o una anticorrelación.
Una fórmula que se utiliza a menudo es la del coeficiente de correlación.
Las redes sociales como Linkedin o Facebook usan las correlaciones para los contactos.
Una correlación no significa causalidad.
Es muy fácil establecer relaciones falsas. En estadística, se llaman relaciones espurias. Si encuentras la causa real de una correlación, el valor añadido será mucho mayor.
La mejor forma de evitar una relación espuria es seguir el método científico. Las preguntas deben estar bien formuladas y loss prejuicios no deben afectar a los resultados.
Analítica predictiva
La recolección de datos hace referencia al pasado. Cómo recolectar distintos tipos de datos, y someterlos a análisis estadísticos, que son el punto de partida del verdadero conocimiento.
La analítica predictiva es un tipo de ciencia de datos.
La ciencia de datos se basa en aplicar el método científico a los datos.
La analítica predictiva usa esos resultados y los transforma en acciones concretas.
Agrupa una variedad de técnicas estadísticas de modelización, aprendizaje automático y minería de datos que analiza los datos actuales e históricos reales para hacer predicciones acerca del futuro o acontecimientos no conocidos.
En el ámbito de los negocios los modelos predictivos extraen patrones de los datos históricos y transaccionales para identificar riesgos y oportunidades.
Los modelos predictivos identifican relaciones entre diferentes factores que permiten valorar riesgos o probabilidades asociadas sobre la base de un conjunto de condiciones, guiando así al decisor durante las operaciones de la organización.
Minería de datos o exploración de datos
Introducción
El término es un concepto de moda, y es frecuentemente mal utilizado para referirse a cualquier forma de datos a gran escala o procesamiento de la información (recolección, extracción, almacenamiento, análisis y estadísticas).
También se ha generalizado a cualquier tipo de sistema informático de apoyo a decisiones, incluyendo la inteligencia artificial, aprendizaje automático y la inteligencia empresarial.
En el uso de la palabra, el término clave es el descubrimiento, comúnmente se define como "la detección de algo nuevo".
Incluso el popular libro "La minería de datos: sistema de prácticas herramientas de aprendizaje y técnicas con Java" (que cubre todo el material de aprendizaje automático) originalmente iba a ser llamado simplemente "la máquina de aprendizaje práctico", y el término "minería de datos" se añadió por razones de marketing.
A menudo, los términos más generales "(gran escala) el análisis de datos", o "análisis" o cuando se refieren a los métodos actuales, la inteligencia artificial y aprendizaje automático, son más apropiados.
La tarea de minería de datos real es el análisis automático o semi-automático de grandes cantidades de datos para extraer patrones interesantes hasta ahora desconocidos, como los grupos de registros de datos (análisis clúster), registros poco usuales (la detección de anomalías) y dependencias (minería por reglas de asociación).
Esto generalmente implica el uso de técnicas de bases de datos como los índices espaciales. Estos patrones pueden entonces ser vistos como una especie de resumen de los datos de entrada, y pueden ser utilizados en el análisis adicional o, por ejemplo, en el aprendizaje automático y análisis predictivo.
Por ejemplo, el paso de minería de datos podría identificar varios grupos en los datos, que luego pueden ser utilizados para obtener resultados más precisos de predicción por un sistema de soporte de decisiones.
Ni la recolección de datos, la preparación de datos, ni la interpretación de los resultados y la información son parte de la etapa de minería de datos, pero que pertenecen a todo el proceso Knowledge Discovery in Databases (KDD - Knowledge Discovery in Databases, la extracción de conocimiento es la creación de conocimiento a partir de fuentes estructuradas y no estructuradas) como pasos adicionales.
Minería de datos o exploración de datos
La minería de datos o exploración de datos (es la etapa de análisis de "Knowledge Discovery in Databases" o KDD) es un campo de la estadística y las ciencias de la computación referido al proceso que intenta descubrir patrones en grandes volúmenes de conjuntos de datos.
Utiliza los métodos de la inteligencia artificial, aprendizaje automático, estadística y sistemas de bases de datos.
La minería de datos o exploración de datos es la etapa de análisis de "Knowledge Discovery in Databases" o KDD es un campo de la estadística y las ciencias de la computación referido al proceso que intenta descubrir patrones en grandes volúmenes de conjuntos de datos.
Objetivo de la Minería de datos o exploración de datos
El objetivo general del proceso de minería de datos consiste en explorar o extraer información de un conjunto de datos y transformarla en una estructura comprensible para su uso posterior.
Además de la etapa de análisis en bruto, supone aspectos de gestión de datos y de bases de datos, de procesamiento de datos, del modelo y de las consideraciones de inferencia, de métricas de intereses, de consideraciones de la teoría de la complejidad computacional, de post-procesamiento de las estructuras descubiertas, de la visualización y de la actualización en línea.
Con la minería de datos se pueden obtener patrones y tendencias existentes en los datos, que se pueden recopilar y definir en un modelo de minería de datos para aplicar al conjunto definitivo de datos a evaluar.
La minería de datos ayuda a analizar los datos, permite la comprensión de los mismos para entonces intentar obtener conclusiones de los datos para cierto beneficio esperado.
Explorar los datos para encontrar reglas y patrones para intentar explicar o entender el comportamiento de los datos, con lo cual se podrían realizar predicciones
Una de las aplicaiones empresariales de la minería de datos podría ser mejorar la atención al cliente para ofrecer los productos y servicios que pudieran necesitar. Otro uso es en el clima para predicciones metereoloóicas. En banca, fidelización de clientes y prevención de fraudes. Seguros para evaluación de riesgos. Marketing, Etc.
Cuando se tiene un modelo es necesario aplicar estadísticas para comprobar su fiabilidad.
Mineros o exploradores de datos
Son personas que se dedican al análisis de datos, descubrir patrones para aportar información valiosa en la toma de decisiones.
¿Qué es necesario tener en cuenta para el análisis de los datos?
Se tiene dependencia de la calidad, cantidad y tipo de datos para un correcto análisis. Los datos deben ser: completos, precisos y confiables.
CRISP-DM Cross Industry Standard Process for Data Mining
Historia
CRISP-DM fue concebido en 1996. En 1997 se puso en marcha como un proyecto de la Unión Europea bajo la iniciativa de financiación ESPRIT.
El proyecto fue dirigido por cinco empresas: SPSS, Teradata, Daimler AG, NCR y Ohra, una compañía de seguros
CRISP
Se trata de un modelo estándar abierto del proceso que describe los enfoques comunes que utilizan los expertos en minería de datos. Es el modelo analítico más usado.
Método probado para orientar sus trabajos de minería de datos.
- Como metodología, incluye descripciones de las fases normales de un proyecto, las tareas necesarias en cada fase y una explicación de las relaciones entre las tareas.
- Como modelo de proceso, CRISP-DM ofrece un resumen del ciclo vital de minería de datos.
- Comprensión del negocio,
- Comprensión de los datos,
- Preparación de los datos,
- Fase de Modelado,
- Evaluación e
- Implantación
Cada fase es descompuesta en varias tareas generales de segundo nivel.
Las tareas generales se proyectan a tareas específicas, pero en ningún momento se propone como realizarlas.
Es decir, CRISP-DM establece un conjunto de tareas y actividades para cada fase del proyecto pero no especifica cómo llevarlas a cabo.

Las flechas en el diagrama indican las dependencias más importantes y frecuentes entre fases.
El círculo exterior en el diagrama simboliza la naturaleza cíclica de la minería de datos en sí.
Un proceso de minería de datos continúa después del despliegue de una solución.
Las lecciones aprendidas durante el proceso pueden provocar nuevas preguntas de negocio, a menudo más centradas y posteriores procesos de minería de datos se beneficiarán de la experiencia de los anteriores.
Guía de CRISP-DM de IBM SPSS Modeler
Algoritmos en minería de datos
Un algoritmo en minería de datos (o aprendizaje automático) es un conjunto de heurísticas y cálculos que permiten crear un modelo a partir de datos.
Para crear un modelo, el algoritmo analiza primero los datos proporcionados, en busca de tipos específicos de patrones o tendencias.
El algoritmo usa los resultados de este análisis en un gran número de iteraciones para determinar los parámetros óptimos para crear el modelo de minería de datos.
A continuación, estos parámetros se aplican en todo el conjunto de datos para extraer patrones procesables y estadísticas detalladas.
- Algoritmos de clasificación, que predicen una o más variables discretas, basándose en los demás atributos del conjunto de datos.
- Algoritmos de regresión, que predicen una o más variables numéricas continuas, como pérdidas o ganancias, basándose en otros atributos del conjunto de datos.
- Algoritmos de segmentación, que dividen los datos en grupos, o clústeres, de elementos que tienen propiedades similares.
- Algoritmos de asociación, que buscan correlaciones entre diferentes atributos de un conjunto de datos. La aplicación más común de esta clase de algoritmo es la creación de reglas de asociación, que pueden usarse en un análisis de la cesta de compra.
- Algoritmos de análisis de secuencias resumen las secuencias frecuentes o episodios en los datos, como una serie de clics en un sitio web o una serie de eventos de registro que preceden al mantenimiento del equipo.
- Analizar los requerimientos empresariales
- Definir el ámbito del problema
- Definir las métricas
- Determinar el objetivo final del proyecto
Secuencia
En el campo de la minería de datos y extracción de conocimiento, la minería de secuencias es un caso particular de la minería de datos estructurados.
Consiste en encontrar patrones estadísticamente relevantes en colecciones de datos que están representados de forma secuencial.
Debido a la frecuencia con que aparecen este tipo de datos en escenarios de aplicaciones reales, esta técnica constituye uno de los métodos más populares de descubrimiento de patrones.
Los patrones frecuentes obtenidos durante el minado de secuencias, se usan en tareas de detección de dependencias funcionales, predicción de tendencias, interpretación de fenómenos y como soporte de decisiones en estrategias de producción.